
 Every second of every day, thousands of bits of information are being created and updated. Connectivity across devices and people proliferates every day, bringing undiscovered relationships and knowledge to light.
Every second of every day, thousands of bits of information are being created and updated. Connectivity across devices and people proliferates every day, bringing undiscovered relationships and knowledge to light.
Naturally, some of these pieces of data can be harnessed actionably to grow, reform, and develop businesses, ideas, and existing management strategies. The tremendous growth of data sets, when used appropriately, can help organizations that are beginning to adopt relatively new-age strategies and technologies like IoT, artificial intelligence, targeted marketing, and automation.
The ability of a company to differentiate itself from an ocean of other similar ones already in the loop of automation and AI depends on its capacity and excellence in managing relevant data. Every moment that data grows exponentially is an opportunity for businesses to exploit data to their advantage.
Data is not an abstract luxury that affects only the paper nowadays. When leveraged correctly, it can be used to detect insights affecting the bottom lines of organizations.
The first step to adopting a data-based approach to management and business development is understanding the relevance and quality of a data piece. Not all data is relevant to your needs, and that which is, might not be good enough to be useful. If a data piece lacks a reasonable degree of accuracy, it is as good as zilch.
Low-quality data can undercut your business and hamper productivity in more ways than one. Since properly utilized data translates to cold, hard cash today, organizations must segregate useful data from bad ones.
Why Should You Invest in Good Data?
According to a Harvard Business Review report, poor data quality delays and denies the power of machine learning and its application in the business world. The software world’s favorite maxim, “Garbage in – Garbage Out,” is equally valid for data management.
If your data management teams work on unnecessarily complicated pieces of data that lack substance, they are likely to produce reports that prompt other departments to produce bad results. For example, if the data collected on a newly released software is terrible, the report prepared on it will be incomplete and faulty. This will prevent the software development cell from making useful improvements to the program and soon cause it to perform poorly in the market.
According to Forrester Research, one-third of data analysts utilize 40% of their overall working time to validate and vet data later used for strategic decision-making. Hours of decreased productivity and redundancy later, they are still not able to produce optimum and useful reports.
In some businesses, this redundant time can directly translate into overspending or underpayments. A series of adverse financial impacts arise as a result of flawed data – increased operating costs, missed opportunities, reduction or delay in cash flow, decreased revenues, and overbearing penalties. Revenue leakage and overhead costs also make up significant portions of the overall loss caused by bad data.
Good data, on the other hand, helps your organization make positive leaps in terms of revenue growth, customer servicing, and productivity. Good-quality data gives individuals and teams the confidence to produce efficient outputs because they are spared from the hassle of navigating through complex yet useless data. When these outputs are trustworthy, it allows for zero decision-making risks and reduced guesswork.
Monetary Impacts of Bad Data
Both small and big brands have fallen prey to bad data. One of the worst examples of losses attributed to poor data came from Silicon Valley giant Apple in 2012. When Apple rolled out its Maps, it quickly became apparent that the underlying data was faulty, and the product was soon labeled “barely usable.”
Subsequent efforts to fix and update Apple Maps were also based on bad data causing the company to lose millions. No questions arise on the quality of Apple’s data management infrastructure. What leads to failure is the company’s bad database.
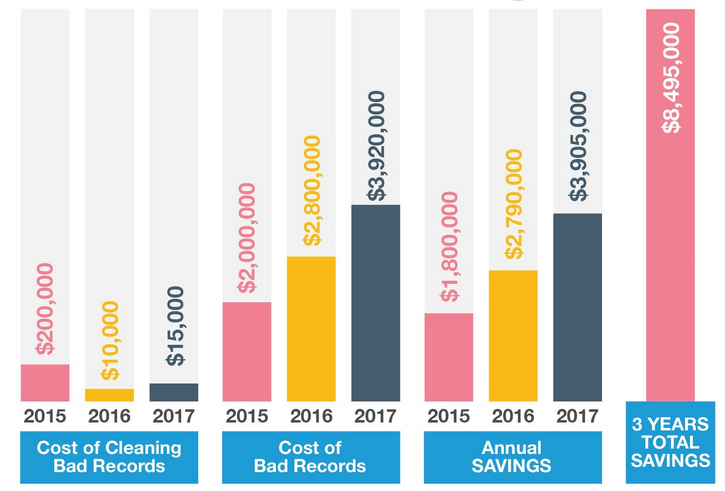
A Gartner research further points out that organizations lose around $15 million per year just because of poor data quality. Inaccurate or duplicate data, as concluded by an Experian Research, impacts the bottom line of 88% brands directly and causes a total of 12% revenue loss. Both of these researches show that regardless of the efficiency of data scientists an organization employs, inadequate judgments are made every day because of erroneous data.
Since data integration is the foundation for traditional data management, duplicate, and cumbersome data can challenge even the best of data analysis and discovery tools.
The quality of data matters as much as the quality of your data management infrastructure. Investing in expensive data management software is both expensive and useless if your organization uses poor data in hopes of saving a few bucks.
Bad data might appear cheap initially, but lost revenue and overhead costs exceed the costs of acquiring good data by several thousand. Directly lost revenue from poor data involves inefficient communication that fails to convert to sales, wrong property information in insurance and poor customer retention due to reputational damage.
Such immense losses further point out the necessity of brands to invest in data that is easy to navigate, high-quality, and trusted. Data monetization is supposed to become one of the most significant revenue sources for a brand by 2025. Keeping this in mind, organizations must not shy away from spending a little extra to ensure better data quality.
In the future, high-quality data will not just provide a competitive advantage to brands, but also become a competitive necessity. Allocating funds for the acquisition of good data and cutting off funding sources for bad data is crucial for avoiding the terrible consequences of data quality mishaps.
If you have already spent significantly on poor data, take basic steps to govern the data. To do this, you must create a team with sufficient knowledge regarding the importance of data quality and follow by setting objectives and goals for data quality assurance. After ensuring governance, eliminate redundancy by abandoning irrelevant data, regardless of the quality.
Once you have the relevant data with you, install process and routines to examine and improve data quality. Remember that the volume of data is not as significant as its quality; hence ensure that you take adequate steps to acquire top-quality data. Merge databases, erase silos across departments, and automate data quality assurance as far as is achievable.
The steps mentioned above work best if your business is too deep into a poor data cycle. However, remember that they take extra time and effort, which you could have easily avoided by investing in good data in the first place. Always buy centralized and certified data and analyze it using optimization software to reduce errors, improve services, and march toward corporate success.






